
News, Peer Groups and Market Data
Sign-up for the latest news and insights from Enhance, delivered direct to your inbox.
Building Investment Restrictions
Earlier this month, Justin Simpson’s #TechTuesday post detailed the basic functionality of our new investment restrictions module within our proprietary FinTech platform, Mosaic, and the kind of restrictions we see placed on the portfolios we monitor.
To follow on from this insight, I want to explore a difficulty that we encountered during the design of this feature - from a software engineering perspective - and how we used some of the key principles of Object-Oriented Programming to overcome this challenge.
The Background
One of the key drivers for the rebuild of Mosaic was to allow us to leverage technology to consistently, accurately, and automatically verify the suitability of a portfolio's investments.
To achieve this, we needed to develop a way for users to easily define sets of rules that the platform would use to process a portfolio's data.
Our initial implementation of this concept was, admittedly, rather naïve. We knew that the vast majority of restrictions that might be placed on a portfolio were those that were checking either the values of individual assets within a category type, or the sum thereof, against some proportion of the portfolio’s overall value. For example, ‘the total amount invested in fixed income assets can be no greater than 30% of the portfolio’s value’.
This is easy to implement programmatically as we simply need to allow a user to select the category that we need to test, choose whether we should test each asset individually or as whole, and select the proportion of the portfolio’s value that these assets should be tested against. Internally, we needed to compare the two values against each other in order to successfully identify a restriction breach.
It was a solid start; the process allowed us to capture the majority of the common restrictions that we would need to test against, such as hard limits against certain domiciles (where we would just set the upper limit to be zero) and limits on concentration of assets within an asset class or industry. We knew that this system wouldn’t handle all types of restrictions, but it had allowed us to put our data to work and enhance the service that we provide.
While it was a step forward in the automation of data processing, we realised that, in order to fully exploit our application, we needed to expand this functionality to capture and automatically assess as many restrictions as possible.
The Challenge
Why are investment restrictions difficult for us to ‘explain’ to a computer? To answer this simply; the language used. The problem lays in how we translate the restrictions from English into something that a computer can understand.
Here is an example of a restriction:
‘The sum of the portfolio’s equity assets denominated in GBP must be less than the largest of 30% of the portfolio’s value, 40% of the portfolio’s cash position, and £500,000.'
This is (relatively!) easy for us to read and understand, but converting this restriction into a set of rules that a computer can interpret is more challenging.
Keep on scrolling for a visual representation of how this restriction looks in Mosaic…
It became very clear very quickly that we needed to thoughtfully design the structure that these restrictions would take in our database and carefully consider how we would enable users to easily create them within Mosaic.
The Solution
Firstly, we worked out which common elements are shared across the restrictions. For example, subsets of the portfolio’s assets, ways to combine said subsets, and aggregate values and metrics that we could calculate against the various types of information stored within our database.
Next, we needed to decide how the relationships between the elements would work and how it could be displayed to the user. In our design meetings, we represented the restrictions as flowchart-like tree structures; from a user interface perspective, this was an intuitive way to allow users to build rule sets as well.
We needed a system where the elements could be arranged in almost any order. This makes it vitally important that each element is able to function completely independently of its place in the overall structure and not require information about other elements that make up the restriction.
To achieve this, we designed a system where each element would only respond to one command – to resolve itself – and would then return a standardised type of data structure. Each element would handle this command differently depending on its function.
The final part of the puzzle was to ensure that each element that sat above others in the 'tree' hierarchy would ask their child/sub-elements to resolve as part of their own resolution.
Essentially, the ‘resolve’ instruction gets passed down the tree, from parent element to child element. Once you reach the bottom, data is passed back up the tree from child element to parent element, with each element performing a transformation on the data before passing it on.
This design closely follows three of the four ‘pillars’ of object-oriented programming: abstraction, encapsulation and polymorphism. These ideas require that each of the various objects that we handle (such as portfolios, benchmarks, clients and balances) interact with each other by exposing high-level commands that produce predictable responses. In this case, each of our elements has one command - to ‘resolve’ - and always returns a predictable data type. Each element is concerned only with how it should function.
So, what does this look like and how does it work in practice?
Do you remember the 9-point restriction we shared as an example above? Here is how it is structured in flowchart-format or, as aforementioned, in a language that the computer understands!
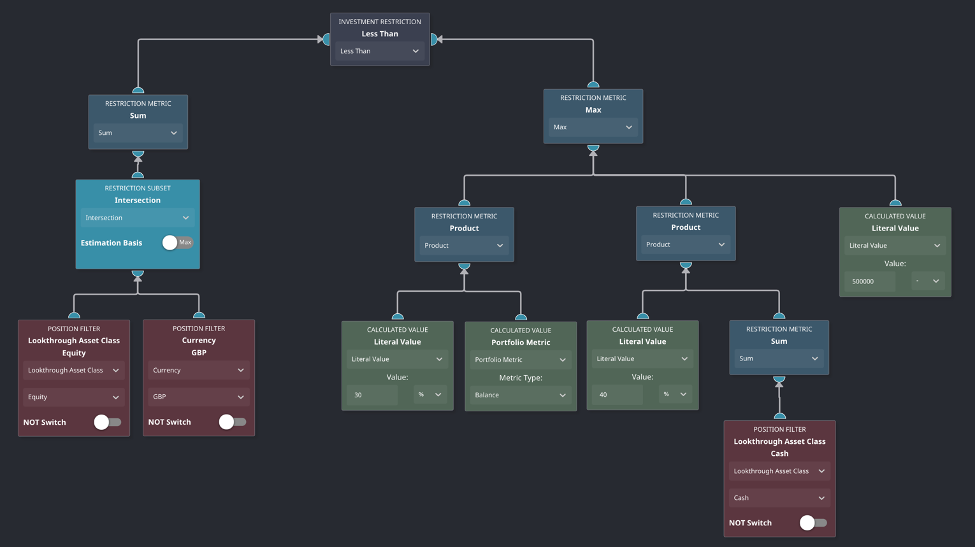
N.B. Parts of this feature are still undergoing testing, and, therefore, some of the naming conventions are yet to be confirmed.
The Benefits
The two key benefits of this design are:
Flexibility
It can be arranged to different levels of complexity ad nauseam, while, at the same time, each element that makes up a restriction doesn’t know anything about the restriction to which it is contributing. It is only interested in telling its child-element(s) to ‘resolve’ and handling the data that its child-elements pass back to it.
Implementation
When working on this feature as a team, we were able to split the work so that each team member could work on an element within the system without having to know anything about the implementation of any of the other elements. This allowed us to avoid merge conflicts and work independently, yet simultaneously, on the feature.
These benefits were instrumental in developing our investment restrictions module; both in the quality of resulting code and the efficiencies we gained in the development process itself.
As developers, we often get bogged down in creating complex new design patterns to implement features. However, when it really comes down to it, simple principles that have stood the test of time can result in a cleaner and more successful outcome.
Sign-up for the latest news and insights from Enhance, delivered direct to your inbox.
